 目标检测
目标检测

DL基础-卷积神经网络(CNN)简易教程
11fendouai 发布于 2020-06-30

作者|Renu Khandelwal 编译|VK 来源|Medium 本篇文章我们将学习什么是CNN, CNN如何利用大脑的启发进行物体识别,CNN是如何工作的。 让我们来了解一下我们的大脑是如何识别图像的 根据诺贝尔奖获得者Hubel和Wiesel教授的说法,视觉区域V1由简单...
阅读(6560)评论(0)赞 (2)
fendouai 发布于 2020-06-30
作者|Renu Khandelwal 编译|VK 来源|Medium 本篇文章我们将学习什么是CNN, CNN如何利用大脑的启发进行物体识别,CNN是如何工作的。 让我们来了解一下我们的大脑是如何识别图像的 根据诺贝尔奖获得者Hubel和Wiesel教授的说法,视觉区域V1由简单...
阅读(6560)评论(0)赞 (2)
fendouai 发布于 2020-07-01
统计学习 随着实验数据规模的迅速增长,机器学习成为了一种越来越重要的技术。 它解决的问题包括:从不同的观测数据实现对应的预测函数、对观测数据进行分类、以及从未标记的数据集中学习到相关统计信息。 本教程将使用机器学习技术在现有的数据集中进行统计推断,从而去学习统计学习相关技术的使用...
阅读(6392)评论(0)赞 (0)
fendouai 发布于 2020-07-01
通过机器的眼睛去探索 如果我们想让机器学会思考,就需要教他们学会如何用视觉去看周围环境。—— 斯坦福大学AI实验室和斯坦福视觉实验室主任李飞飞 使计算机或手机等机器看到周围环境的现象称为计算机视觉。机器仿生人眼的研究工作可以追溯到50年代,从那时起,我们已经走了很长一段路。计算机...
阅读(7731)评论(0)赞 (2)
fendouai 发布于 2020-07-01

作者|Richmond Alake 编译|Flin 来源|towardsdatascience 包含有关薪资期望,工作量,可交付成果以及更多关键差异的信息。 介绍 人工智能是当前一个有趣的行业,机器学习从业者现在是“酷孩子”。 但是,即使在“酷孩子”中,机器学习从业者群体之间也有...
阅读(5189)评论(0)赞 (1)
fendouai 发布于 2020-07-01
介绍 机器学习工程师这一角色通常与编程,软件实现,数据分析等专业技能相关联。 尽管专业技能对于拥有称职的ML工程师非常重要,但对于ML工程师来说,还有一系列软技能是同样重要的。 在本文中,我不仅会提高你对这些软技能的认识,还将提供一些技巧和建议,以帮助你的个人发展和技能培养。 沟...
阅读(4547)评论(0)赞 (1)
fendouai 发布于 2020-07-01
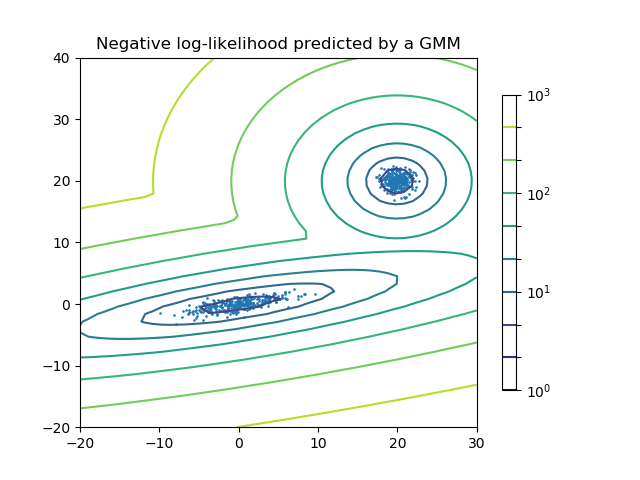
2.1. 高斯混合模型(Gaussian mixture models) sklearn.mixture是一个可以用来学习高斯混合模型(支持对角线(diagonal),球面(spherical),平移(tied)和全协方差矩阵(full covariance matrices))...
阅读(6812)评论(0)赞 (0)
fendouai 发布于 2020-07-01

实例分析 管道流 经过之前的文章,我们已经知道一些估计器可以进行数据转换,一些估计器可以预测变量。我们还可以创建组合估计器同时完成上述两项任务: import numpy as np import matplotlib.pyplot as plt import pandas as...
阅读(4972)评论(0)赞 (1)
fendouai 发布于 2020-07-01
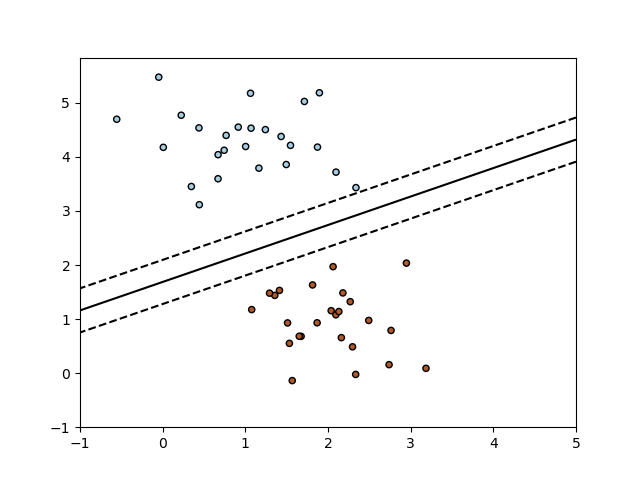
随机梯度下降法(SGD)是一种简单但非常有效的方法,主要用于凸损失函数下线性分类器的判别式学习(例如(线性)支持向量机和Logistic回归)。尽管SGD在机器学习社区中已经存在很长时间了,但在最近大规模学习的背景下,它又引起了相当多的关注。 SGD已成功应用于文本分类和自然语言...
阅读(5385)评论(0)赞 (0)
fendouai 发布于 2020-06-30
章节内容 在本节中,我们将介绍在scikit-learn中所使用的机器学习的基础知识点,并且给出一个简单的代码示例。 机器学习:问题设置 通常,一个机器学习问题会通过学习n个数据样本,然后去预测未知数据的属性。如果每个样本都不止一个属性,即一个多维属性(也称为多元 数据),则称其...
阅读(4888)评论(0)赞 (0)
fendouai 发布于 2020-06-30
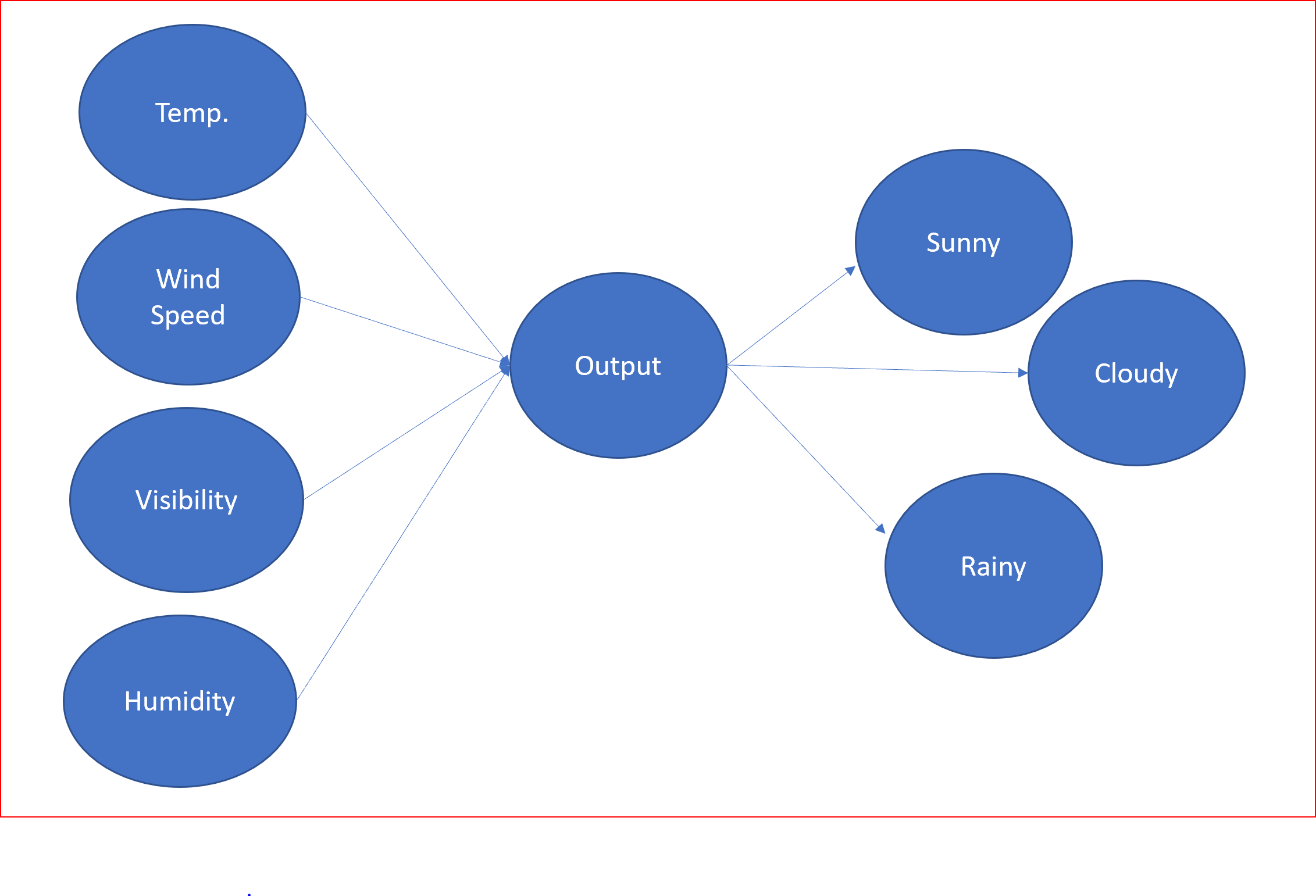
作者|Renu Khandelwal 编译|VK 来源|Medium 在这篇文章中,我们将去学习神经网络的基础知识。 本篇文章的学习需要对机器学习有着基本理解,如果你学习过一些机器学习算法,那就更好了。 首先简单介绍一下人工神经网络,也叫ANN。 很多机器学习算法的灵感来自于大自...
阅读(4882)评论(0)赞 (0)
fendouai 发布于 2020-06-30

DL基础-神经网络的批标准化 作者|Emrick Sinitambirivoutin 编译|VK 来源|Towards Data Science 训练学习系统的一个主要假设是在整个训练过程中输入分布是保持不变的。对于简单地将输入数据映射到某些适当输出的线性模型,这种条件总是能满足...
阅读(4726)评论(0)赞 (0)
fendouai 发布于 2020-03-08

scikit-learn(sklearn)是机器学习中经典的专用库,涵盖了几乎所有主流机器学习算法,包括分类(Classfication)、聚类(Clustering)、回归(Regression)、降维(Dimensionality Reduction)等,还包括了特征提取,数...
阅读(7427)评论(0)赞 (1)
fendouai 发布于 2020-03-04
MMDetection专栏开篇 引言 MMDetection是一款优秀的基于PyTorch的深度学习目标检测工具箱,由香港中文大学(CUHK)多媒体实验室(mmlab)开发。基本上支持所有当前SOTA二阶段的目标检测算法,比如faster rcnn,mask rcnn,r-fcn...
阅读(11471)评论(0)赞 (2)
fendouai 发布于 2020-03-04
Detectron2专栏开篇 专栏介绍 Detectron是构建在Caffe2和Python之上,实现了10多篇计算机视觉最新的成果。Facebook AI研究院又开源了Detectron的升级版,也就是接下来我们要介绍的:Detectron2。 Detectron2 是 Fac...
阅读(15958)评论(1)赞 (2)
fendouai 发布于 2020-03-09
Python进阶 《Python进阶》是《Intermediate Python》的中文译本, 谨以此献给进击的 Python 和 Python 程序员们! 前言 Python,作为一个”老练”、”小清新”的开发语言,已受到广大才男...
阅读(4992)评论(0)赞 (2)

