 目标检测
目标检测
2.1. 高斯混合模型(Gaussian mixture models)
sklearn.mixture是一个可以用来学习高斯混合模型(支持对角线(diagonal),球面(spherical),平移(tied)和全协方差矩阵(full covariance matrices))的工具包,同时它还提供了对混合分布进行抽样,以及从数据训练拟合混合模型的功能。它还提供了一些工具帮助我们确定分量的合适数量。
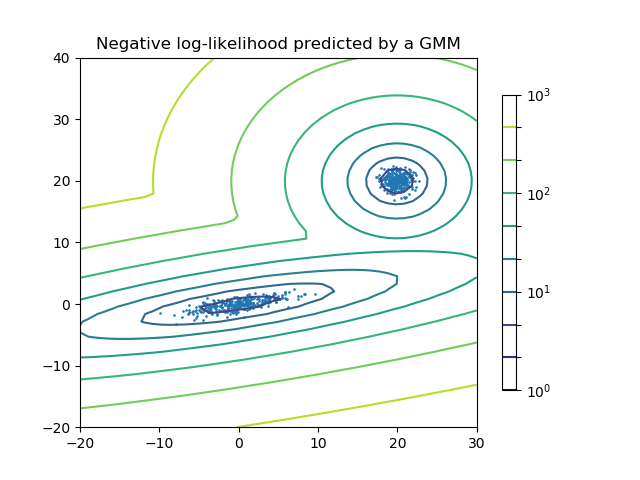 F
F
二元高斯混合模型(Two-component Gaussian mixture model): 数据点,以及模型的等概率平面(equi-probability surfaces)。
高斯混合模型是一种概率模型,它假定所有数据点都是由有限个参数未知的高斯分布进行混合来产生的。可以认为混合模型是k均值聚类的推广,它包含了关于数据的协方差结构和在高斯分布中的中心信息。
Scikit-learn实现了不同的类来估计高斯混合模型,这些模型对应着不同的估计策略,下面将进行详细介绍。
2.1.1. 高斯混合(Gaussian Mixture)
GaussianMixture对象实现了用于拟合高斯混合模型的期望最大化(expectation-maximization)(EM)算法。同时它还可以绘制多元模型的置信椭圆体,并通过计算贝叶斯信息准则来评估数据中的聚类数量。该类对象提供了从训练数据中学习高斯混合模型的GaussianMixture.fit方法。在给定测试数据的情况下,可以使用GaussianMixture.predict方法为每个样本分配它可能属于的高斯分布。
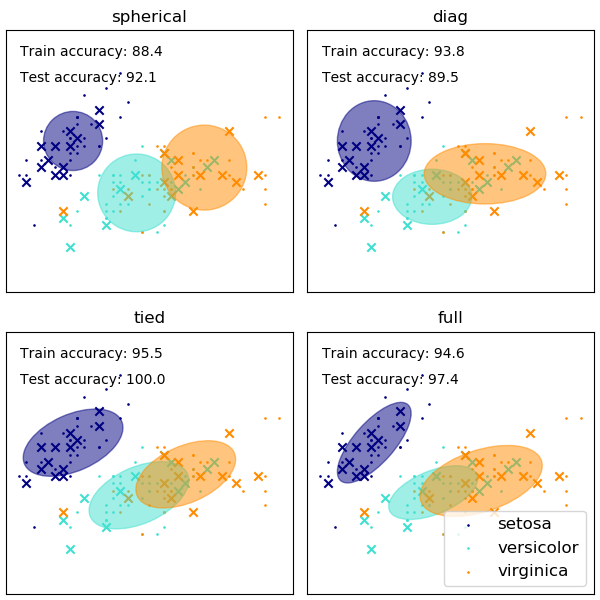
GaussianMixture有不同的选项来约束不同类型估计方法的协方差:球面(spherical)、对角线(diagonal)、平移(tied)或完全协方差(full covariance)。
案例:
- 有关在鸢尾属植物数据集上使用高斯混合进行聚类的案例,详情请参见GMM协方差。
- 有关绘制密度估算值的案例,详情请参见高斯混合的密度估算值。
2.1.1.1. GaussianMixture的优缺点
2.1.1.1.1. 优点
| 速度: | 这是学习混合模型最快的算法 |
|---|---|
| 不可知论(Agnostic): | 由于此算法仅仅最大化似然函数(likelihood),因此 它不会把均值偏向到0,以及使聚类大小偏向于可能适用或者可能不适用的特殊结构。 |
2.1.1.1.2. 缺点
| 奇异性(Singularities): | 当每个混合模型没有足够多的样本点时,估算协方差会变得困难起来,同时算法会发散和去找具有无穷大似然函数值的解,解决这个问题,需要人为地对协方差进行正则化。 |
|---|---|
| 分量的数量(Number of components): | 这个算法会用所有它能用的分量,所以在没有外部信息的情况下需要留存数据或者用信息理论准则来决定用多少分量。 |
2.1.1.2. 选择经典高斯混合模型中分量的数量
一种高效的方法是利用BIC(贝叶斯信息准则)来选择高斯混合的分量数。理论上,它仅当在渐进状态(asymptotic regime )下可以恢复正确的分量数(即如果有大量数据可用,并且假设这些数据实际上是一个混合高斯模型独立同分布生成的)。请注意,使用变分贝叶斯高斯混合(Variational Bayesian Gaussian mixture)可避免高斯混合模型中分量数的选择。
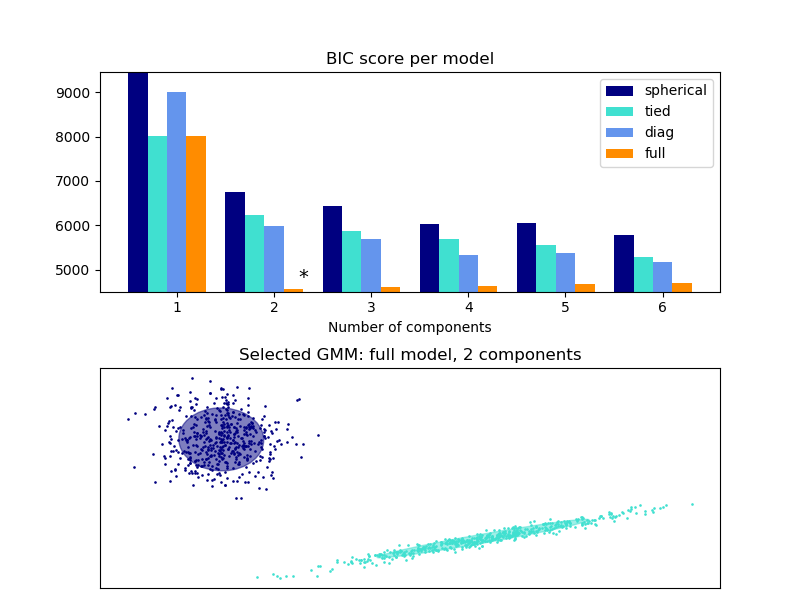
案例:
2.1.1.3. 估计算法:期望最大化(EM)
从未标记的数据中学习高斯混合模型的主要困难在于,通常不知道样本点来自于哪个潜在分量(如果可以获取到这些信息,就可以很容易通过相应的数据点,拟合每个独立的高斯分布)。期望最大化(Expectation-maximization) 是一种经过验证的统计算法,可以通过迭代过程来解决此问题。首先,假设我们产生了一些随机分量(随机选择数据点的中心做为随机分量,数据点的中心可以用k-means算法得到,或者在原点周围正态分布的样本点做为随机分量),并且为每个样本点计算由模型的每个分量生成该样本点的概率。然后,调整模型参数来最大化模型生成这些数据点的概率。重复这个过程就可以保证模型总会收敛到局部最优解。
2.1.2. 变分贝叶斯高斯混合(Variational Bayesian Gaussian Mixture)
BayesianGaussianMixture实现了具有变分推理算法的高斯混合模型变体。这个类的API和GaussianMixture是类似的。
2.1.2.1. 估计算法:变分推理
变分推理是期望最大化的扩展,它最大化了模型(包括先验条件)的下界而不是数据的概率。变分方法的原理与期望最大化相同(这两者都是迭代算法,两个步骤包括在寻找每个混合模型产生每个点的概率和根据所分配的样本点来拟合混合模型,两个步骤之间迭代交替运行), 但是变分方法通过整合先验分布信息来增加正则化限制。这避免了期望最大化解决方案中常出现的奇异性,但是也对模型带来了微小的偏差。变分方法计算过程通常较慢,但不会慢到无法使用。
由于它的贝叶斯特性,变分算法比期望最大化(EM)需要更多的超参数,其中最重要的就是浓度参数weight_concentration_prior。低浓度先验使模型的大部分权重放在少数分量上,其余分量的权重则趋近0。而高浓度先验将使混合模型中的大部分分量都有一定的权重。
BayesianGaussianMixture实现了两种先验权重分布:一种是利用狄利克雷分布(Dirichlet distribution)的有限混合模型,另一种是利用狄利克雷过程(Dirichlet Process)的无限混合模型。在实际应用上,狄利克雷过程推理算法是近似的,并且使用了具有固定最大分量数的截尾分布(称之为Stick-breaking representation)。使用的分量数实际上几乎取决于数据。
下图比较了权重浓度先验的不同类型(参数weight_concentration_prior_type) 和该类型不同的权重浓度先验值(参数weight_concentration_prior)。在这里,我们可以看到weight_concentration_prior参数的值对获得有效的激活分量数(即权重较大的分量的数量)有很大影响。我们也能注意到当先验是‘dirichlet_distribution’ 类型时,大的浓度权重先验会导致更均匀的权重,然而‘dirichlet_process’类型(默认类型)却不是这样。
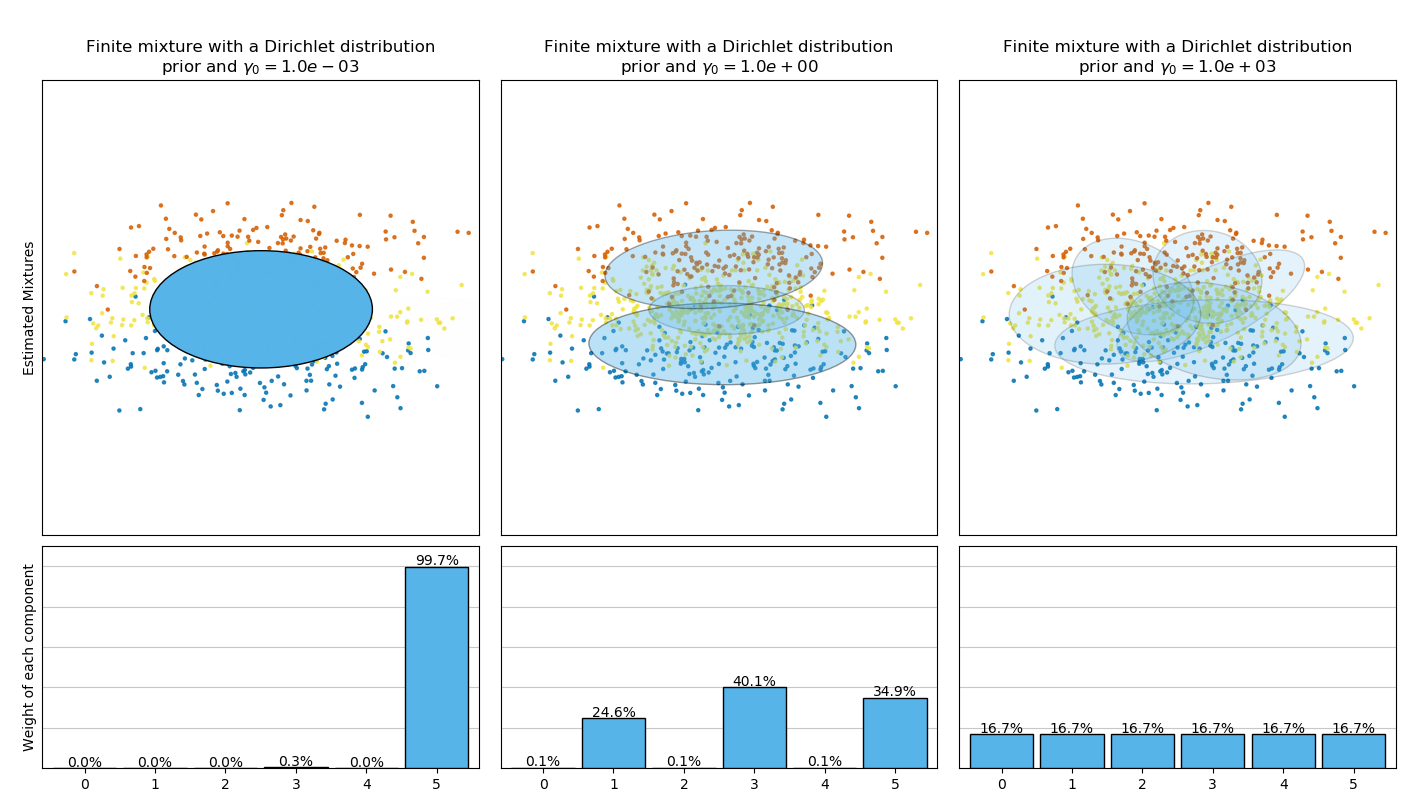
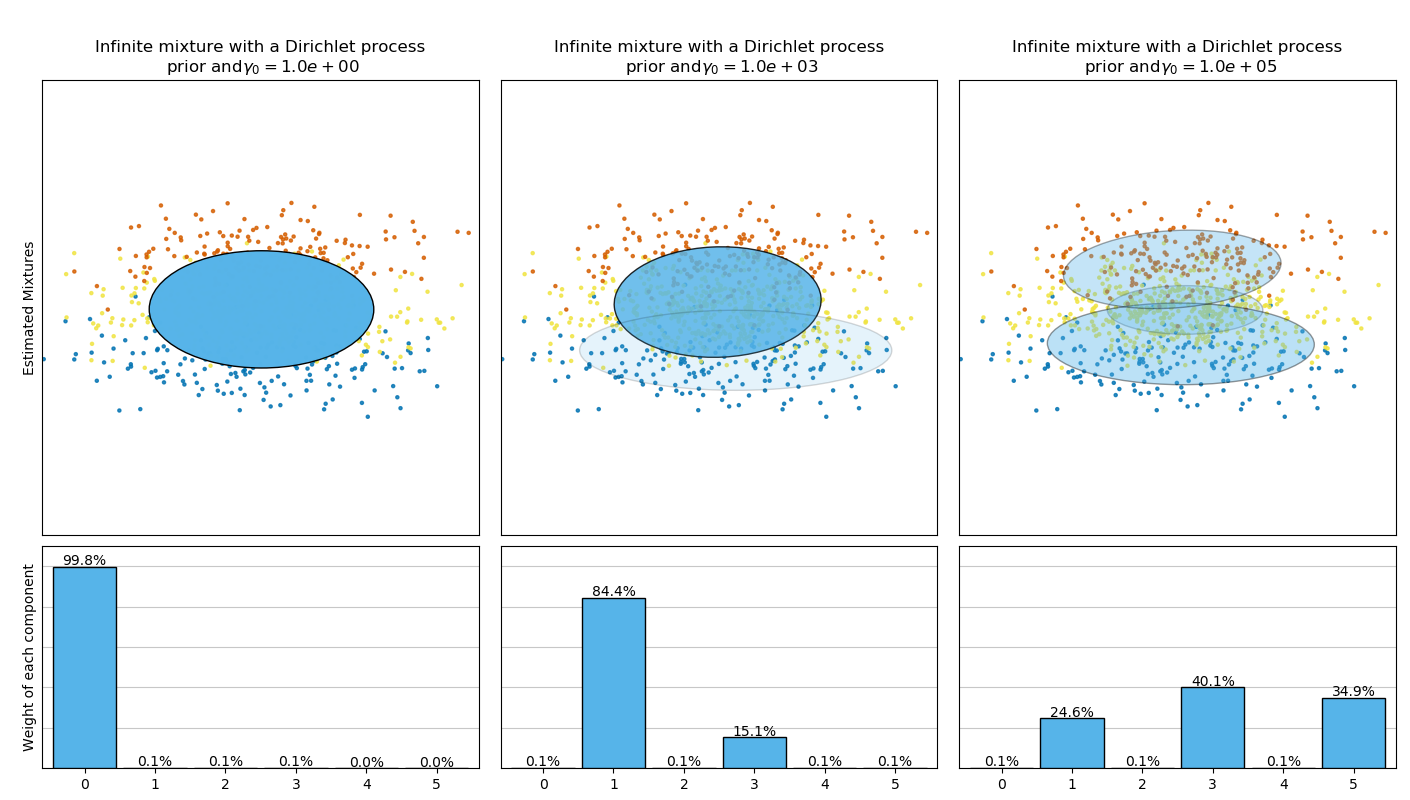
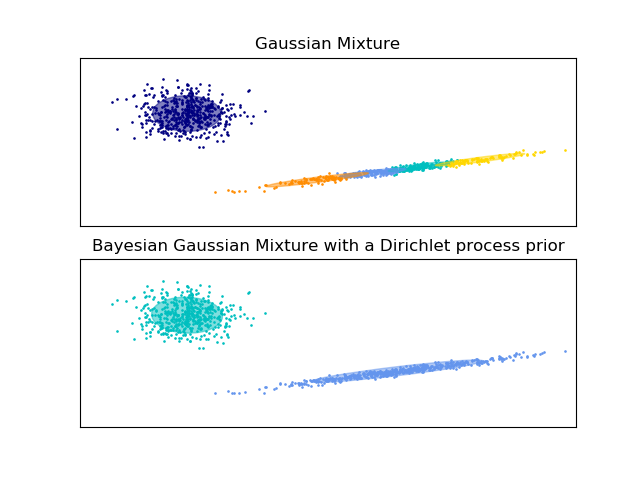
下面的例子比较了分量数目固定的高斯混合模型与带有狄利克雷过程先验(Dirichlet process prior)的变分高斯混合模型。这里,使用5个分量的典型高斯混合模型在由2个聚类组成的数据集上进行拟合。我们可以看到,具有狄利克雷过程先验的变分高斯混合模型可以将自身限制在 2 个分量,而高斯混合模型必须按照用户事先设置的固定数量的分量来拟合数据。在例子中,用户设置了 n_components=5,这不符合该数据集的真正的生成分布(generative distribution)。注意到当只有非常少量的观测,带有狄利克雷过程先验的变分高斯混合模型会采取保守的方式,只拟合一个分量。
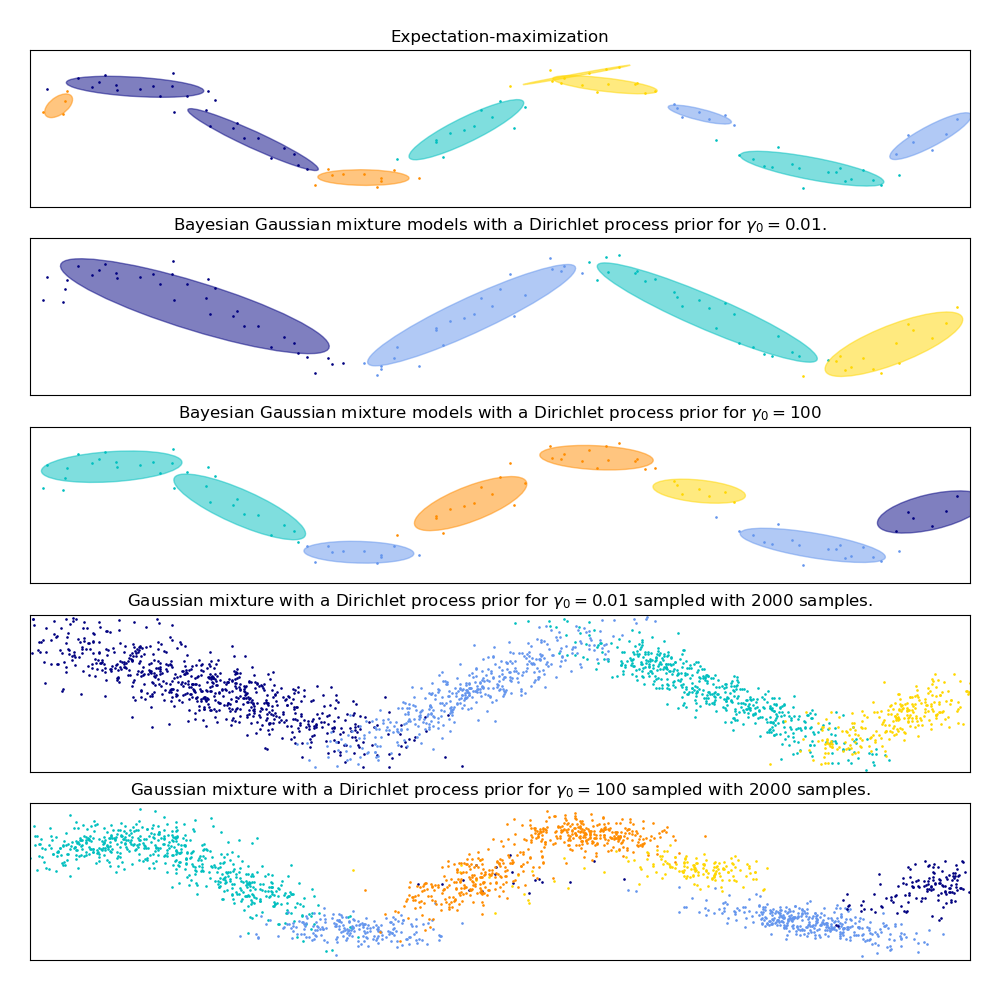
在下图,我们拟合了没有很好被高斯混合描述的数据集。调整BayesianGaussianMixture的参数weight_concentration_prior用于控制拟合此数据的分量数。我们还在最后两个图上展示了从两个混合模型产生的随机抽样。
案例:
- 一个用GaussianMixture 和BayesianGaussianMixture绘制信赖椭圆面的案例,详情请参见高斯混合模型-椭圆面。
- 高斯混合模型-正弦曲线显示使用GaussianMixture和BayesianGaussianMixture拟合正弦波。
- 一个用BayesianGaussianMixture的
weight_concentration_prior_type和weight_concentration_prior参数的不同值来绘制信赖椭圆面的案例,详情请参见变分贝叶斯高斯混合的浓度先验类型分析 。
2.1.2.2.变分推理BayesianGaussianMixture的优缺点
2.1.2.2.1. 优点
| 自动选择: | 当weight_concentration_prior足够小以及n_components比模型实际需要的更大时,变分贝叶斯混合模型有一个天生的优势就是让一些混合权重值趋近0,这让模型可以自动选择合适的有效分量数,而这仅仅需要提供分量的数量上限即可。但是请注意,“理想”的激活分量数只在应用场景中比较明确,在数据挖掘参数设置中通常并不明确。 |
|---|---|
| 对参数的数量不敏感: | 在有限模型中,总是用尽所有可以用的分量,因此不同数量的components会产生不同的解。与上述有限模型不同,带有狄利克雷过程先验的变分推理(weight_concentration_prior_type='dirichlet_process')在参数变化的时候结果并不会改变太多,这使之更稳定和需要更少的调优。 |
| 正则化: | 由于结合了先验信息,变分的解比期望最大化(EM)的解具有更少的病理特征(pathological special cases)。 |
2.1.2.2.2. 缺点
| 速度: | 变分推理所需要的额外参数化使推理速度变慢,尽管并没有慢很多。 |
|---|---|
| 超参数: | 这个算法需要一个额外进行实验调优的超参数。 |
| 有偏的: | 在推理算法中存在许多隐含的偏差(如果用到狄利克雷过程也会有偏差),每当这些偏差和数据之间不匹配时,用有限模型可能会拟合更好的模型。 |
2.1.2.3. 狄利克雷过程(The Dirichlet Process)
我们在这里描述了关于狄利克雷过程的变分推理算法。狄利克雷过程是在具有无限大,无限制的分区数的聚类上的先验概率分布。相比于有限高斯混合模型,变分技术让我们在推理时间几乎没有惩罚的情况下把先验结构纳入到高斯混合模型。
一个重要的问题是狄利克雷过程是如何实现用无限大的,无限制的聚类数来实现正确的结果。本文档不做出完整的解释,但是您可以看这里折棍过程(stick breaking process)来帮助你理解它。折棍过程是狄利克雷过程的衍生。每次从一个单位长度的棍子(stick)开始,每一步都折断棍子的一部分,每次把每个棍子(stick)的长度联想成落入一组混合点的比例。最后,为了表示无限混合,我们联想成最后的每个棍子(stick)剩下的部分到没有落入其他组的点的比例。每段的长度是随机变量,概率与浓度参数成比例。较小的浓度值将单位长度分成较大的棍子(stick)段(即定义更集中的分布)。较高的浓度值将生成更小的棍子(stick)段(即增加非零权重的分量数)。
狄利克雷过程的变分推理技术仍然可以对无限混合模型进行有限近似,但是不必先验地指定要使用的分量数,只要指定浓度参数和一个关于混合分量数量的上界就可以了。这个上界,假定它比真正的分量数要高一点,也仅会影响算法复杂度,而不会影响算法实际用到的分量的真实数量。
©2007-2019,scikit-learn开发人员(BSD许可证)。 显示此页面源码
未经允许不得转载,请联系zhouas@hotmail.com获取授权:目标检测 » sklearn 高斯混合模型
